Can you trust an AI revenue forecast more than your sales leader's gut?
TL;DR
On average accuracy, usually yes — statistical models have matched or beaten expert judgment in decades of head-to-head research. But trust doesn't follow accuracy: after a miss, a human forecaster gets re-trusted and a model doesn't, especially in financial decisions. Run a model baseline with logged human overrides, and narrate every miss the way a human would.
What the research shows
The accuracy question is the settled half. Since Meehl (1954), head-to-head comparisons of statistical prediction against expert judgment have, in most studied domains, come out even or in the model's favor — mostly because models don't sandbag, don't get happy ears, and apply the same logic to every deal in the pipeline.
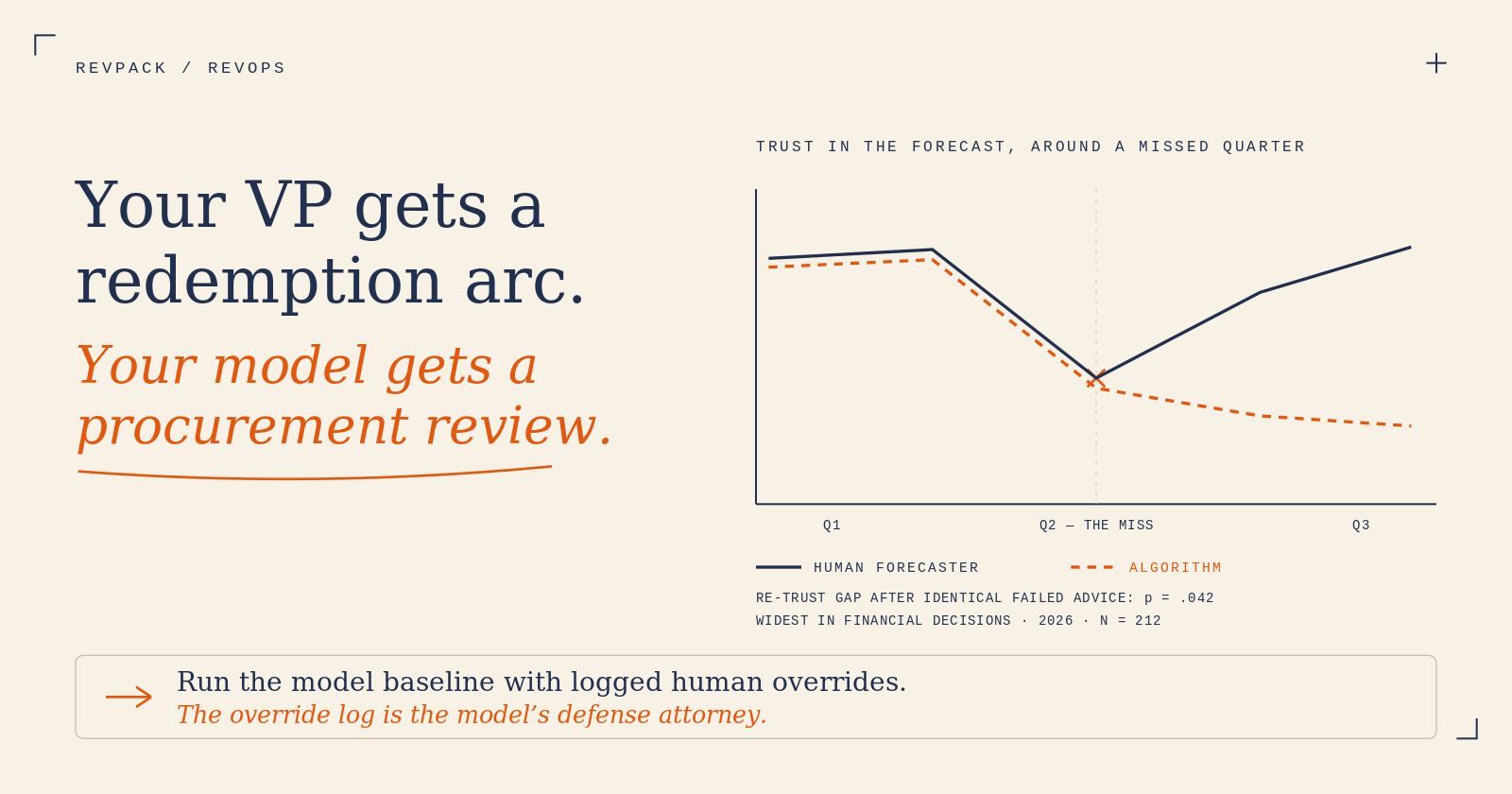
The trust question is the unsettled half, and it's the one that kills forecasting rollouts. In our cofounder Adam's experimental study (master's thesis, Warsaw, 2026; N = 212), participants received failing advice from either an AI algorithm or a human expert across three scenarios — including a stock-market investment, the closest analogue to a revenue call. Three findings matter here.
After the same failed advice, participants were significantly less willing to reuse the algorithm than the human (p = .042).
The financial scenario produced the strongest disappointment of the three contexts — money decisions hurt more, whoever advised them.
And the asymmetry peaked exactly there (interaction p = .021): willingness to re-trust the expert after a failure was at its highest in the investment scenario, while willingness to re-trust the algorithm stayed flat across all contexts. In money decisions, humans get second chances. Models don't.
The board meeting version
Your VP of Sales misses a quarter: "the market shifted, two champions left, he's already adjusting the commit process." The model misses the same quarter: "the AI doesn't work."
A human forecaster gets a redemption arc. A model gets a procurement review.
Notice what's actually happening: the VP's miss gets a narrative, and narratives are how trust survives errors. The model produced a number with no story attached, so the miss becomes the whole story. This is the perfect automation schema in a boardroom — we expect machines to be precise, so a machine's error reads as a defect rather than a variance.
Which means the practical question isn't "is the model more accurate than the VP?" It probably is. The question is whether the model survives its first missed quarter long enough for that accuracy to compound — and that's a design decision, not a data-science one.
Three forecast setups, one that survives a miss
The hybrid wins for an unglamorous reason: the override log is the model's defense attorney. When the quarter misses, you can decompose it — the model was right and an override moved the number, or an override caught what the model couldn't see, or the model itself missed and you can name which input lied to it. Every one of those is a narrative. Narratives are what trust survives on.
| Setup | Average Accuracy | After a Missed Quarter | The Board Story |
|---|---|---|---|
| Pure model | Highest on a clean, high-volume pipeline | Trust collapses; tool quietly shelved | “A black box missed” |
| Model baseline + logged human overrides | Near-model, plus handling of shocks the data can't see | Miss is decomposable: was it the model or the overrides? | “The system proposes, named humans dispose — here's the log” |
There's a prerequisite, and it's the one CFOs already suspect: a model fed by drifting deal stages and stale close dates isn't a forecasting problem, it's a hygiene problem wearing a forecasting costume. The model will faithfully formalize whatever fiction the pipeline contains — we've covered that failure mode separately.
Pre-agree the error budget
The single highest-leverage move comes before the first forecast ships: agree with the board what normal error looks like, in writing. A range, not a number. Who explains a miss, in what format, within how many days. What gets reviewed at three misses versus one.
It sounds bureaucratic. It's the opposite — it's the mechanism that converts a miss from a referendum on the tool into a variance within a known budget. Human forecasters have enjoyed this arrangement forever; nobody fires the VP over one bad quarter, because everyone agreed quarters are uncertain. Extend the model the same contract, because the research says nobody will extend it the benefit of the doubt voluntarily.
A forecast model without a miss-communication plan is a one-quarter experiment.
If your model and your CRM disagree every Monday, the audit usually starts with deal-stage hygiene, not the algorithm — happy to show you how we run it.
Frequently asked questions
Are AI forecasts actually more accurate than sales leaders?
In head-to-head research on statistical versus expert prediction, going back to Meehl (1954), models match or beat expert judgment in most domains — chiefly through consistency, not brilliance. On a specific pipeline it depends on deal volume and data hygiene; thin pipelines and dirty stage data can make a model worse than the VP it replaced.
If models are more accurate, why does everyone still sanity-check them?
Because trust in algorithms is asymmetric: experimental research, including a 2026 study (N = 212), shows people are significantly less willing to re-trust an algorithm than a human after one failure — and the gap is widest in financial decisions. The sanity-check is pre-positioned blame insurance, and it's rational given how organizations punish unexplained misses.
Should the model replace the VP's commit?
No — run them in parallel with logged overrides. The model sets the baseline; named humans adjust for what data can't see, and every adjustment is recorded with a reason. You get near-model accuracy plus something a pure model can never give the board: a decomposable explanation when a quarter misses.
What should we do after the model's first big miss?
Decompose it publicly within days: model error, override error, or input error. Name the cause and the fix in the same meeting. Trust in a human rebounds on its own; trust in a model only rebounds if someone narrates the recovery.
Does bad CRM hygiene break AI forecasting?
It's the most common cause of "the model doesn't work." A forecast model trained on inflated stages and stale close dates formalizes the fiction with confidence. Audit stage definitions, exit criteria, and close-date discipline before judging the model — often the model was fine and the pipeline was lying.
Related reading
Primary Experimental Research
- Stachowicz, A. (2026). Algorithm or Expert? An Analysis of Regret and Disappointment in the Context of Unsuccessful Decisional Advice. Master's Thesis, Akademia Leona Koźmińskiego, Warsaw.
- Data Scope: A 3x2x2 experimental design evaluating trust recovery after advice failure across 212 participants.
- Key Finding: Acting on advice explains 44% of future trust variance, while the source (AI vs. Human) explains only 2%.
Theoretical Frameworks
- Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm Aversion: People Erroneously Avoid Algorithms After Seeing Them Err. Journal of Experimental Psychology: General.
- This study established that humans lose confidence in algorithms more rapidly than in human experts after witnessing identical errors.
- Madhavan, P., & Wiegmann, D. A. (2007). Similarities and Differences Between Human–Human and Human–Automation Trust. Theoretical Issues in Ergonomics Science.
- The foundational research for the "perfect automation schema," explaining why machine errors are more surprising and less forgivable than human ones.
- Aggarwal et al. (2024). Generative Engine Optimization (GEO). Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
- Research confirming that citing statistics and named sources increases the likelihood of content being quoted by AI answer engines by up to 31-41%.


