Why do sales reps ignore AI recommendations and go with gut feel?
TL;DR
Two reasons, both measurable. People punish an algorithm's mistakes harder than a human's, so the first visible miss ends the experiment. And trust in any advice source is built by acting on it — reps who only observe a tool never form trust at all. Fix the first-action problem before you buy more accuracy.
What the research shows
Algorithm aversion is one of the better-replicated findings in decision research. Dietvorst, Simmons, and Massey (2015) put people in front of a human and an algorithm making the same forecasting errors; participants dropped the algorithm faster, even when it was the more accurate of the two. A human's error reads as natural. A machine's error reads as broken.
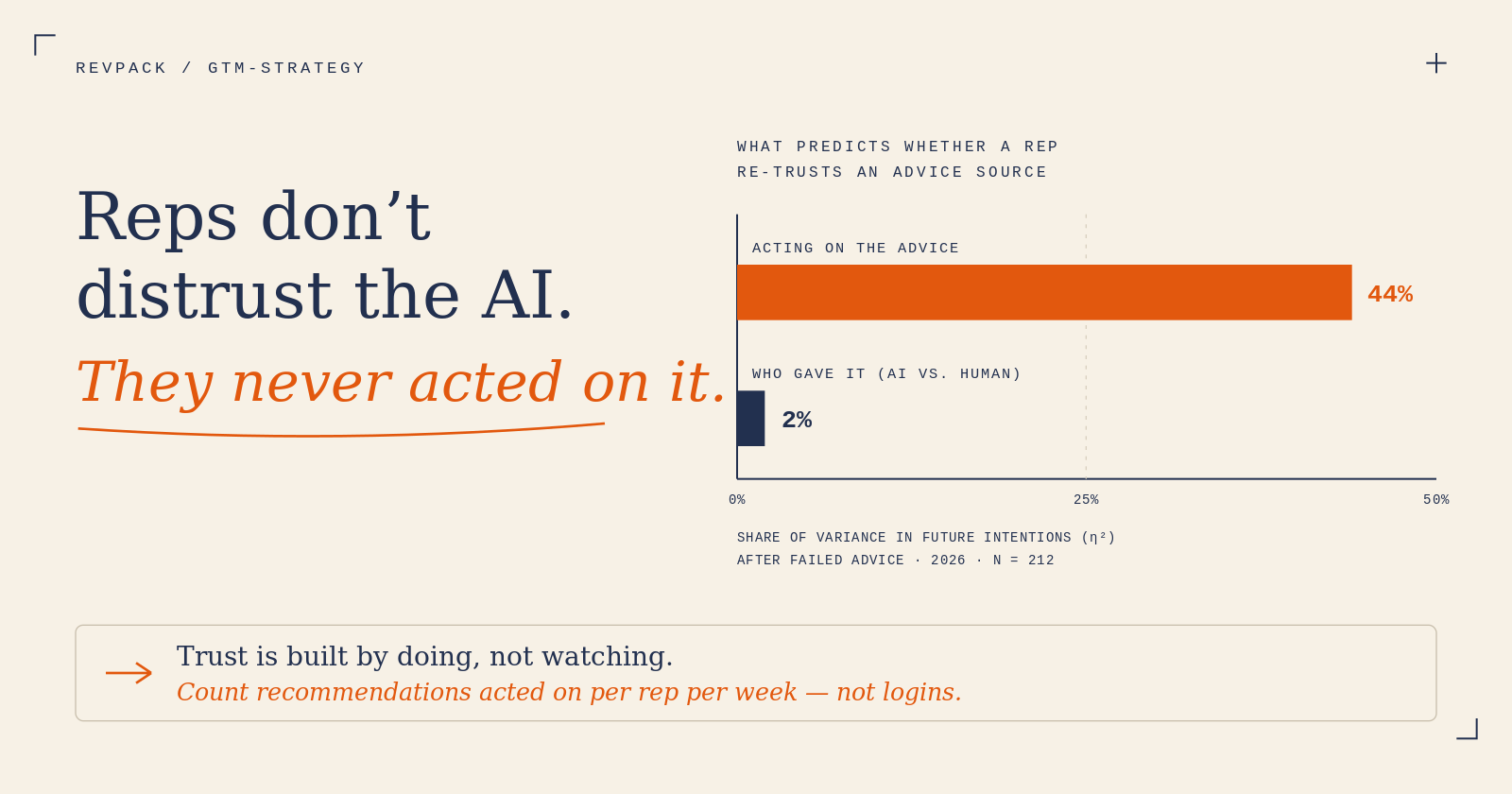
Our cofounder Adam tested the downstream behavior in a controlled experiment for his master's thesis (Warsaw, 2026; N = 212). Every participant received advice that failed — the design varied only the source (AI algorithm versus human expert) and whether the advice was followed. After the identical bad outcome, willingness to use the algorithm again was significantly lower than willingness to return to the human (p = .042).
The result that should change how you run pilots, though, is the other one. Whether the person had acted on the advice was by far the strongest predictor of whether they'd trust the source again — it explained about 44% of the variance in future intentions (p < .001), dwarfing the effect of who gave the advice. People who followed a recommendation, even into a bad outcome, stayed open to the source. People who merely received it did not.
Read that again from your pipeline meeting's perspective: a rep who acts on a recommendation that fails is more likely to keep using the tool than a rep who watches it from a distance being right.
The observation trap
Here's the pilot pattern that fails on schedule. The team buys intent data or an account-prioritization tool. Nobody's workflow changes — the signals live in a panel beside the queue, "so reps can use it when it's useful." Logins look fine for two weeks. Then the panel becomes wallpaper, the champion starts forwarding screenshots to prove value, and eleven months later the renewal conversation opens with "does anyone actually use this?"
The standard diagnosis is change management. The mechanism is simpler: nobody ever acted, so nobody ever built trust, so there was nothing to keep. Observation doesn't create commitment — and meanwhile every rep was waiting, consciously or not, for the tool's first visible miss to justify the gut feel they never stopped using.
Gut feel has structural advantages in this fight. It's free, it's instant, and when it's wrong, the rep absorbs the miss as experience rather than evidence against a vendor. The tool enjoys none of that forgiveness. It has to win on a tilted field, and accuracy alone doesn't tilt it back.
What actually moves reps from gut to signal
The action-scoped pilot works because it's built on what the evidence says forms trust: doing, repeatedly, at low stakes. Five accounts per rep per week is enough. The accounts are real, the activity is logged, and the rep experiences the tool's hit rate personally instead of hearing about it.
| Rollout Pattern | What Reps Do | First Visible Miss | What Happens to Trust |
|---|---|---|---|
| Big-bang | Triage the whole queue by score from day one | Days in, in front of everyone | One bad MQL becomes the model's reputation; reps revert to gut |
| Scoped action pilot | Work a short, high-precision slate weekly | Later, inside a habit that's already producing wins | Action compounds into trust; misses get post-mortemed, not memed |
Then run the first miss like a post-mortem, not a trial. When the tool flags an account that goes nowhere, name the cause in the same meeting where you'd celebrate its wins: which signal misfired, what changed in the model, what would catch it next time. A human advisor gets to explain a bad call and stay credible. Your tool can't speak — someone has to do it on its behalf, or the asymmetry does its work.
The adoption metric follows from all of this. Stop counting logins. Count recommendations acted on, per rep, per week. It's the only number the research says predicts whether the tool is alive in a year.
If you've got a pilot dying quietly right now, we've diagnosed a few of those — write us and we'll tell you what we'd check first.
Frequently asked questions
Is algorithm aversion actually proven, or is it consultant folklore?
It's an experimental finding, first demonstrated by Dietvorst, Simmons, and Massey (2015) and replicated since, including in our cofounder's 2026 study (N = 212), where participants were significantly less willing to reuse an algorithm than a human expert after an identical failed recommendation.
Why does a rep trust a colleague's tip over a tool with a better hit rate?
Because the two aren't judged by the same rules. Human errors read as natural and are quickly forgiven; machine errors read as defects. Accuracy determines which source is right more often — forgiveness determines which one survives being wrong.
Should we just mandate that reps follow the AI's recommendations?
Mandating action does build usage, but forced reliance turns the first visible miss into a referendum. A scoped requirement — a few tool-picked accounts per rep per week, with overrides allowed and logged — gets you the trust-building action without staking the rollout on a perfect first month.
How long does it take for reps to trust a new tool?
Trust tracks acted-on recommendations, not calendar time. A rep who works five tool-picked accounts weekly accumulates more trust in six weeks than a rep who's had the dashboard open for a year. Measure recommendations acted on per rep per week and you'll see the curve directly.
Our reps say the AI's picks are "obviously wrong." Now what?
Treat it as signal — sometimes it's the model: stale data, vanity signals. And sometimes it's the tilted field, where one bad pick erased ten good ones. Run the picks against rep-chosen accounts for a month and publish both conversion rates. Whichever way it comes out, you've replaced an argument with a record.
Primary Experimental Research
Stachowicz, A. (2026). Algorithm or Expert? An Analysis of Regret and Disappointment in the Context of Unsuccessful Decisional Advice. Master's Thesis, Akademia Leona Koźmińskiego, Warsaw.
Data Scope: A 3×2×2 experimental design evaluating trust recovery after advice failure across 212 participants.
Key Finding: Acting on advice explains 44% of future trust variance, while the source (AI vs. Human) explains only 2%.
(Link unavailable publicly if the thesis has not yet been deposited in an online repository.)
Theoretical Frameworks
Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm Aversion: People Erroneously Avoid Algorithms After Seeing Them Err. Journal of Experimental Psychology: General.
https://doi.org/10.1037/xge0000033
This study established that humans lose confidence in algorithms more rapidly than in human experts after witnessing identical errors.
Madhavan, P., & Wiegmann, D. A. (2007). Similarities and Differences Between Human–Human and Human–Automation Trust. Theoretical Issues in Ergonomics Science.
https://doi.org/10.1080/14639220500337708
Foundational research behind the "perfect automation schema," explaining why machine errors are often perceived as less forgivable than human errors.
Aggarwal et al. (2024). Generative Engine Optimization (GEO). Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
https://arxiv.org/abs/2311.09735
Research showing that the inclusion of statistics and named sources increases the likelihood of content being surfaced and cited by AI answer engines.
Methodology Note
The statistics regarding trust variance and the "action-based trust" multiplier are derived from the 2026 Warsaw study's analysis of participant intentions following failed recommendations. These findings suggest that the most critical factor in lead scoring adoption is not the math of the model, but the workflow habit of the sales team.


